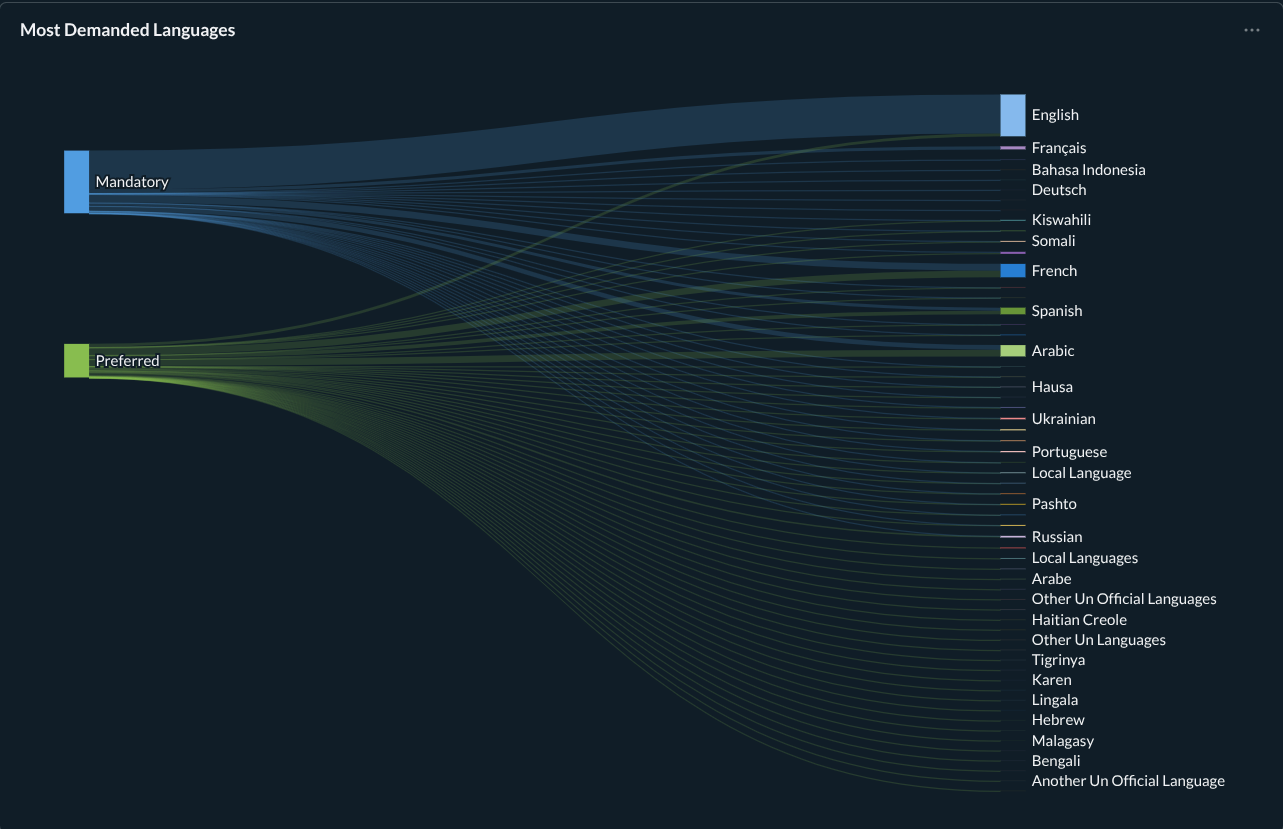
-- Use a Common Table Expression (CTE) to combine and clean the language lists
WITH all_languages AS (
-- First, get, clean, and label all mandatory languages
SELECT
CASE
WHEN LOWER(language_name) IN ('spanish', 'español') THEN 'Spanish'
ELSE INITCAP(language_name) -- Standardizes capitalization for others (e.g., 'english' -> 'English')
END AS language,
'Mandatory' AS requirement_level
FROM
job_llm_extractions,
unnest(mandatory_languages) AS language_name
UNION ALL
-- Second, get, clean, and label all preferred languages
SELECT
CASE
WHEN LOWER(language_name) IN ('spanish', 'español') THEN 'Spanish'
ELSE INITCAP(language_name)
END AS language,
'Preferred' AS requirement_level
FROM
job_llm_extractions,
unnest(preferred_languages) AS language_name
)
-- Finally, group, count, and get the top 145 results
SELECT
language,
requirement_level,
COUNT(*) AS number_of_jobs
FROM
all_languages
WHERE
language IS NOT NULL -- Exclude any potential nulls that might result from empty arrays
GROUP BY
language,
requirement_level
ORDER BY
number_of_jobs DESC -- Changed: Order by the count to find the highest values
LIMIT 90; -- Added: Limit the output to the top 145 rowsThis was the most complicated visualization, and sadly, the worst to see on the mobile phone.
[LLM extraction of new information in Job Descriptions about localization]